
Marco Giannini
Open data, Big Data e data sharing.

A Washington, capitale degli Stati Uniti, è ospitata la Library of Congress, la più grande biblioteca del mondo, con oltre 160 milioni di oggetti tra libri (23 milioni), monografie (14), registrazioni musicali e non (3,6), mappe (5,5), spartiti (7,1), manoscritti e monografie le più diverse (oltre 70). Digitalizzare tutto questo materiale sarebbe un’opera ciclopica: il totale si avvicinerebbe a uno yottabyte, cioè una massa di informazione stipabile in 100 miliardi di hard disk da 10 terabyte, e infatti non si ha notizia che qualcuno al Congresso abbia cominciato a lavorare di scanner.
Però è quel che rimane fuori dalla biblioteca a stupire. Paragonando questa enorme mole di dati a ciò che viene immesso in rete dagli utenti il confronto risulta davvero squilibrato: ogni giorno le banche dati mondiali incamerano meno dell’1% del totale dei dati generati attraverso registrazioni motivate (per esempio transazioni finanziarie) oppure casuali e involontarie (per esempio un passaggio su un video di Youtube). Si parla di quasi 3 milioni di yottabyte al dì, cifra in costante crescita e praticamente impossibile da regolare e analizzare. Qualcuno ha provato a quantificarla, ma il rendiconto rimane un’astrazione, qualcosa di incommensurabile se paragonato alla nostra esperienza concreta. E inoltre invecchia rapidamente.

Una infografica prodotta da Digitalic per render conto delle unità di misura del traffico dei dati su Internet.
Big Data, dove il dato brutale non esiste più.
Questo universo confuso e poco esplorato è il cosiddetto Big Data, un mare di possibilità attraversato da correnti furiose, un caos in urto continuo con la nostra pretesa materiale (si fa per dire, trattandosi comunque di codice binario chiuso in una memoria digitale) di metterlo a frutto.  In questo oceano ciascuno pesca quel che può dotandosi di strumenti di ICT, acronimo di Information and Communication Technology, le quali permettono l’acquisizione massiva di dati e fabbricano sistemi automatizzati per ricavarne significati, tendenze, indicazioni di sviluppo predicibili con l’ausilio di modelli matematici.
In questo oceano ciascuno pesca quel che può dotandosi di strumenti di ICT, acronimo di Information and Communication Technology, le quali permettono l’acquisizione massiva di dati e fabbricano sistemi automatizzati per ricavarne significati, tendenze, indicazioni di sviluppo predicibili con l’ausilio di modelli matematici.
Negli ultimi due decenni tantissime aziende, governi, istituti indipendenti, persino partiti politici e gruppi terroristici si sono dotati di data scientists, cioè di esperti in statistica che applicano algoritmi a dataset con l’intento di ricavarne informazione e progettualità.
![]()
Il più importante sito open della community mondiale: http://www.datasciencecentral.com.
Oggi il Big Data è primariamente un obiettivo per l’applicazione di teorie e tecniche commerciali, e non si vergogna affatto di porsi come strumento di mercato: nei prossimi anni, secondo Forbes, i data scientists scaleranno le posizioni più importanti e meglio remunerate nell’industria e nel commercio mondiale, orientando flussi di denaro e investimenti come fecero i CEO durante il boom dell’economia digitale di inizio secolo.
Pareidoxia: vedo qualcosa che un po’ capisco e la faccio mia (fa anche rima).

Eppure anche l’industria del “Grande Numero” incontra in questo momento un primo “Grande Limite”. Com’è noto le ICT non sempre riescono a generare previsioni affidabili, i sondaggi d’opinione danno per sicuri risultati poi capovolti dal voto (le presidenziali Usa come ultimo episodio della serie, ma un assaggio l’avevamo già avuto qui), le analytics prevedono il successo di pacchetti di azioni sul mercato azionario ma non l’avvento di una nuova crisi globale, studi settoriali sui bias del grande pubblico convincono le case di produzione a investire milioni in serie televisive che si rivelano presto un flop. E così via elencando.
Dunque, se le ICT sono strumenti di misura tanto affidabili, perché sbagliano così spesso?
La risposta va cercata nel nostro approccio generale all’informazione. In linea di massima, noi sappiamo pochissimo di ciò di cui non abbiamo esperienza diretta. Accumuliamo informazioni e le processiamo subito secondo le categorie che conosciamo, ma così facendo ci sbarazziamo del disagio di pensare, perché l’istantaneità ostacola il ragionamento. Se poi lasciamo il compito a un tool tecnologico non fatichiamo nemmeno a copiare e registrare, e l’informazione ci sfiora senza toccarci, andando a depositarsi in qualche archivio dove forse un giorno potremo ritrovarla.
In questo le ICT, più che aiutarci, ci guidano come un pastore conduce un gregge.
Quel che facciamo in pratica è riconoscere un’idea o una sua parte, impossessarcene, farcene portavoce (per esempio condividendo un post su un social network) e propagandarla. La ricordiamo per qualche giorno, e un po’ più a lungo sappiamo dove andarla a cercare quando ci servirà.
Il fatto che la nostra impronta venga stipata in un profilo elettronico certifica la nostra partecipazione, ma ci tiene sufficientemente lontano da essa; mesi o anni dopo, la riguarderemo come una foto di famiglia ormai scolorita. Eppure la traccia resta, e ricostruisce la nostra identità secondo scelte che facciamo quasi inconsapevolmente.
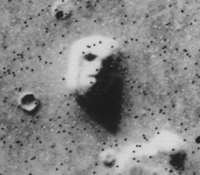
Volto su Marte, una celebre formazione rocciosa sulla superficie di Marte.
Ricalcando la definizione di pareidolia, illusione che ci spinge a riconoscere conformazioni note come un volto umano in aggregazioni casuali, possiamo dire che cercando più o meno a caso finiamo spesso per trovare qualcosa che ci coinvolge a sufficienza per darci un argomento di conversazione: serve una nuova parola per questo processo subcosciente, pareidoxìa, che è alla base del funzionamento delle ICT e della loro crisi.
L’eterna equazione.
Nel centro di questa crisi c’è il consumatore, parola polisemica da tempo oggetto di dibattito: il consumatore di beni, sempre più spesso acquistati in rete, cioè telefoni mobili, libri, gioielli e così via, ma anche il consumatore di informazione. Seguendo un percorso naturale il consumatore dovrebbe evolversi in cittadino, e non solo quando vota, ma più in generale quando si fa delle domande (nessun richiamo al M5S).

Perché anche la crisi della politica parlamentare è imparentata con la non-predicibilità di certi indici: se il cittadino non si sente rappresentato, reagisce disobbedendo a una logica pre-disposta, coniata su misura, e quando ne ha l’occasione si rifugia nell’incomprensibile, tira una “picconata” al sistema perché vuole mantenersi unico. Come individuo diffida dei politici, dei sindacalisti, dei giornalisti, e si nasconde nella categoria di “gente”, popolo, appellativi miti e non enfatici di un tutto che implica ogni cosa, purché assicuri dei tratti di unicità a ciascuno.

Come non vedere in questa deriva l’impronta individualista che alligna nel mondo digitale? Il profilo del cittadino – affidato a un social network o anche solo ricostruito grazie ai cento riflessi lasciati qua e là – attrae come una preda elettronica gli algoritmi di ricerca dati. Questi algoritmi acquisiscono eventi (in forma di clic o di ditata su uno schermo) e li correlano a eventi simili: agiscono senza una causa espressa dall’individuo protagonista (il quale, per via della sopra spiegata pareidoxìa, non ne è nemmeno del tutto consapevole), quindi senza la possibilità di costruire una teoria comportamentale che tiene insieme i suoi gesti e i suoi dati. Questo non può che generare imprecisione, perché non tiene conto della volontà del singolo.
Alla fine il cittadino, in quanto consumatore, non ha aspirazioni né desideri (o almeno non è importante che li abbia perché nessuna macchina sa ascoltarli ma solo, al più, prevederli) e dunque non riesce a scegliere sensatamente. Ritiene di essere emancipato da ogni determinazione, ma lasciando like su un social e comprando e cliccando continua ad esser analizzabile da un algoritmo, in misura sempre maggiore, e ricade in categorie che lui stesso, se ne fosse avvertito, rifiuterebbe.
Gli algoritmi delle ICT in questo sono molto conservatori: non danno risposte su ciò che la gente dice di voler fare, ma solo su ciò che fa senza dirlo (appunto comprare, cliccare, lasciare like). La loro capacità di predire il futuro sta quindi tutta nel saper leggere il passato, supponendo che i due termini siano (e quindi saranno) sempre uguali: un’eterna equazione. In poche parole essi non sanno introdurre nell’analisi, oltre al comportamento dei consumatori, le enormi asimmetrie in termini di potenza tra costoro, nonché la percezione delle ingiustizie che ognuno sente e le sue aspirazioni a porvi fine, restituendogli almeno la proprietà della sua opinione (doxa), per quel poco o tanto che vale.
Come dovrebbe essere utilizzato il Big Data.
Così giungiamo a un aspetto fondamentale, che pure a molti sembra sfuggire: l’informazione generata da tutti noi è – o dovrebbe essere – innanzitutto nostra proprietà. Se non esclusiva, perlomeno ben regolata.
Non a caso al Big Data si affianca e si contrappone sull’asse pubblico – privato l’Open Data, cioè l’insieme dei dati raccolti e utilizzati per motivi di interesse comune, quali trasparenza, partecipazione democratica e politica, miglioramento dei servizi, innovazione scientifica tecnologica e culturale, individuazione di nuova conoscenza che emerge dall’accostamento e combinazione di fonti differenti e dall’osservazione delle rispettive regolarità e difformità.
Molti studi e una gran massa di interventi rendono conto delle potenzialità dell’Open Data, ultimo tra i tanti questo illuminato articolo di Mario Rasetti sul Sole24Ore. Costruire un archivio di dati aperto significa fornire dati senza vincoli di accesso, cioè a chiunque; pertanto gli Open Data non sono in vendita (sarebbe difficile ricavarne qualcosa), se contengono registrazioni personali bisogna richiedere il permesso per consultarli (per esempio le liste dei debitori insolventi consultate dalle banche, in Italia nella Crif; infine quelli governativi sono per legge quasi interamente pubblici in tutto l’Occidente.

Tim Berners-Lee
I cinque gradi di apertura.
Quel che contiene può esser più o meno utile o interessante, ma per prima cosa un buon dataset aperto deve rispondere a dei criteri di accessibilità:
Tim Berners-Lee, tra i fondatori del World Wide Web, ha introdotto una classificazione degli archivi secondo il loro grado di consultabilità e di condivisibilità: si va da una a cinque stelle, ovvero da un minimo che prevede che i dati siano disponibili con una licenza libera (una stella), a dati organizzati in struttura a tabella (due) in formato proprietario come l’Excel, o meglio ancora se in formato libero come il CSV (tre); se i dati sono connotati ciascuno da un indicatore univoco (URI), un utente esterno può costruire un link a un singolo dato (quattro stelle);  infine se i dati sono correlati con altri dati, viene creato un contesto, cioè un aiuto alla lettura (cinque).
infine se i dati sono correlati con altri dati, viene creato un contesto, cioè un aiuto alla lettura (cinque).
Quest’ultimo caso fa riferimento al Relational Database Management System, cioè un apparato che oltre alla consueta etichettatura degli oggetti presenti al suo interno offre la possibilità di aggiungere alla catalogazione la voce “si correla a…”, utile quando si compongono database aperti a oggetti di cui non si conosce in anticipo, prima di assimilarli, forma o sostanza. È questa la base per costruire sistemi a corrispondenze multiple, dove la categorizzazione gerarchica è fondamentale, e la più avanzata – per quanto banale – tecnologia di archiviazione a disposizione del data sharing.

Un esempio di parallel sets, sistema di visualizzazione di datasets gerarchici, elaborato da Robert Kosara: http://kosara.net/publications/Kosara_TVCG_2006.html.
Quel che c’è di buono in giro.
Un breve elenco degli attori più importanti nell’Open Data deve cominciare citando la più nota organizzazione mondiale non profit: Open Knowledge Foundation è stata fondata nel 2004 a Cambridge, raccoglie una pletora di progetti open e li coordina a livello planetario.
![]()
Tra i progetti Open Data notevoli, tutti ad “alta tecnologia”, val la pena ricordare Tax tree Finland (città di Hameenlinna) e Where do my money go, piattaforme che permettono di conoscere l’utilizzo del gettito fiscale.

Siti di approfondimento sull’attività parlamentare, come il danese Folkesting e l’italiano OpenParlamento. Negli Stati Uniti la stessa funzione è assolta tra gli altri da OpenStates. Il fantasioso Findtoilet,  che permette di trovare la toilet pubblica più vicina in tutto il territorio danese, o il neerlandese Vervuilingsalarm che sorveglia la qualità dell’aria sfruttando i dati provenienti dalle centraline di rilevamento. New York City è la città più mappata del mondo, e i servizi che sfruttano i dati aperti sono in parte sotto l’amministrazione cittadina (https://data.cityofnewyork.us/). Invece Mapnificent è attiva in molte città del mondo e permette di conoscere dati di quartiere, prezzi medi delle case, trasporti e infrastrutture sul territorio, e persino i tempi di percorrenza media da un luogo all’intero vicinato.
che permette di trovare la toilet pubblica più vicina in tutto il territorio danese, o il neerlandese Vervuilingsalarm che sorveglia la qualità dell’aria sfruttando i dati provenienti dalle centraline di rilevamento. New York City è la città più mappata del mondo, e i servizi che sfruttano i dati aperti sono in parte sotto l’amministrazione cittadina (https://data.cityofnewyork.us/). Invece Mapnificent è attiva in molte città del mondo e permette di conoscere dati di quartiere, prezzi medi delle case, trasporti e infrastrutture sul territorio, e persino i tempi di percorrenza media da un luogo all’intero vicinato.
I documenti ufficiali dell’Unione Europea, tradotti nelle 24 lingue ufficiali e contenenti migliaia di frasi, sono alla base del servizio di traduzione istantanea di Google Translate. Il sito danese Husetsweb fornisce indirizzi e contatti degli artigiani di zona a disposizione per i servizi casalinghi, sfruttando le pagine gialle e i dati catastali locali. Nella lista seguente ci sono alcuni tra i più noti data server pubblici che forniscono dati grezzi e in qualche caso più sofisticati strumenti di analisi.
Nel mondo: http://global.census.okfn.org/ http://opengovernmentdata.org/
Negli Stati Uniti: http://datausa.io/ http://beta.censusreporter.org/

In Italia: http://www.dati.gov.it/ http://www.agid.gov.it/agenda-digitale/open-data http://www.sciamlab.com/opendatahub/ http://www.datiopen.it/ http://it-city.census.okfn.org/
Esiste anche una branca del giornalismo, detta data journalism o giornalismo di precisione, che in Italia ha una finestra riservata al festival del giornalismo a Perugia: http://www.festivaldelgiornalismo.com/giornalismo-di-precisione/

Per abituarsi a “pensare open”, l’Open Data Institute, fondato tra gli altri dal solito Tim Berners-Lee, ha pensato di proporre Datopolis, un gioco da tavolo il cui scopo è costruire delle infrastrutture pubbliche sfruttando gli Open Data nella città di fantasia chiamata Sheridan.
L’Open Data a misura di persona.
Poiché in molti Paesi la distinzione tra pubblico e privato è differente da quella italiana, gli archivi di dati per l’Open Government sono molto diversi tra loro e appartengono a fondazioni, associazioni e gruppi di interesse. Il criterio più importante resta l’accessibilità, ma per ora non è possibile costruire un sistema di Open Data ordinato e ugualmente efficiente in ogni campo, perché le fonti sono a tutt’oggi diversamente accessibili e soprattutto perché le esigenze individuali degli utenti variano enormemente da persona a persona.
Propongo quest’esempio personale, prodotto in meno di un quarto d’ora, per mostrare come delle ricerche mirate – a parità di risultato – attingano a fonti differenti. Per divertirsi si può provare a rifare lo stesso mappando le proprie necessità e i propri gusti, per misurare quanto l’Open Data sia oggi, oltre che un patrimonio di tutti, una risorsa per ciascuno di noi.
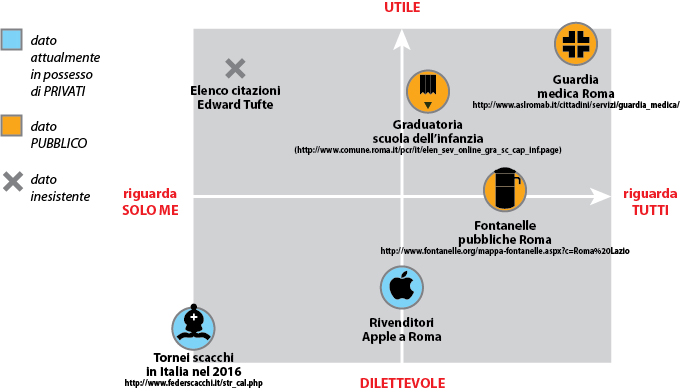
In rosso gli assi su cui ho disposto i risultati delle ricerche: utile/dilettevole, interesse personale/interesse comune. I dati ottenuti riportano il link utilizzato (se disponibile) sotto l’argomento; in un caso (citazioni di Edward Tufte) non è stato possibile trovare in rete un elenco utile.